MySQL 学习笔记
重新开始学习 MySQL,记录学习笔记
看的教学视频是:【韩顺平讲MySQL】零基础一周学会MySQL,讲的蛮不错的
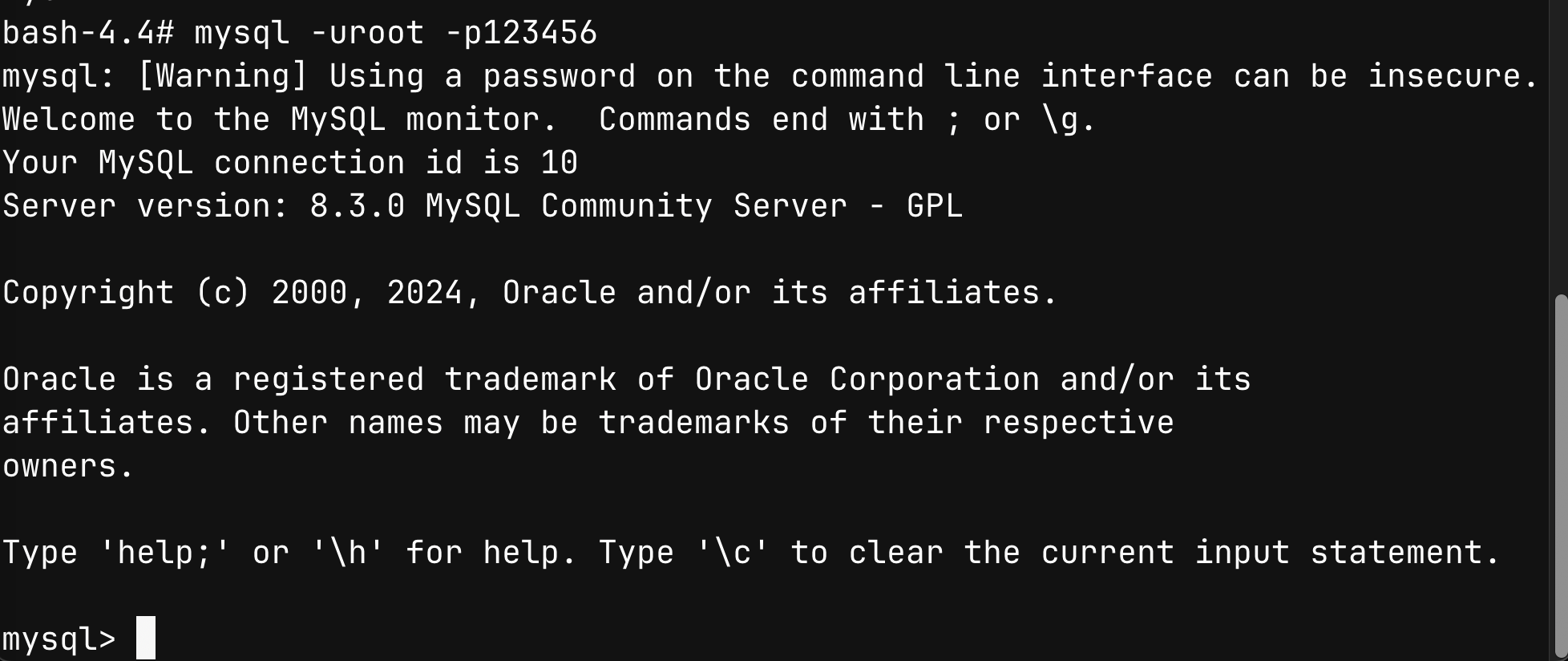
使用命令行连接 MySQL
为了方便演示,用户名都用 root,密码都用 123456 来表示
具体的命令格式:
mysql -h 主机名 -P 端口号 -u用户名 -p123456
其中主机名和端口名号可以省略,不写的话会使用默认值
- 主机名的默认值是:localhost
- 端口的默认值是:3306
比如:
mysql -h localhost -P 3306 -uroot -p123456
等价于
mysql -u root -p123456
出于安全考虑,一般部署到服务器上的 MySQL 服务都不会使用默认的端口号 3306,而是自定义一个端口号
假设现在在服务器 123.456.789.123 上部署了 MySQL 服务,自定义 MySQL 端口号为 7799,那么想要连接到这个 MySQL 的命令如下
mysql -h 123.456.789.123 -P 7799 -uroot -p123456
SQL 语句分类
- DDL:数据定义语句(create 表、库等)
- DML:数据操作语句(增加 insert、修改 update、删除 delete)
- DQL:数据查询语句(select),这个是需要重点学习的
- DCL:数据控制语句(管理数据库,如用户权限 grant revoke)
数据库操作
创建数据库
具体的命令格式:
CREATE DATABASE [IF NOT EXISTS] 数据库名称 CHARACTER SET 数据库字符集 COLLATE 数据库字符集校验/排序规则;
-
IF NOT EXISTS(可选):判断数据库是否已经存在
- 加上 IF NOT EXISTS, 执行创建语句时数据库已存在不做任何操作
- 不加上 IF NOT EXISTS,执行创建语句时数据库已存在创建语句会报错
-
CHARACTER SET(可选):指定数据库的字符集
-
COLLATE(可选):指定数据库的字符集校验/排序规则
示例:
-- 创建数据库 create_db_test ,指定字符集为 utf8mb4,排序规则为 utf8mb4_general_ci
CREATE DATABASE IF NOT EXISTS `create_db_test` CHARACTER SET `utf8mb4` COLLATE `utf8mb4_general_ci`;
常见的数据库字符集和数据库字符集排序规则对比:
| 字符集 (Character Set) | 描述 (Description) | 默认排序规则 (Default Collation) | 描述 (Description) |
|---|---|---|---|
utf8 | UTF-8 Unicode | utf8_general_ci | 一般不区分大小写的 Unicode 排序规则 |
utf8mb4 | UTF-8 Unicode (支持4字节字符) | utf8mb4_general_ci | 一般不区分大小写的 Unicode 排序规则 |
latin1 | 西欧字符集 | latin1_swedish_ci | 瑞典语不区分大小写的排序规则 |
ascii | US ASCII | ascii_general_ci | 一般不区分大小写的 ASCII 排序规则 |
ucs2 | UCS-2 Unicode | ucs2_general_ci | 一般不区分大小写的 UCS-2 排序规则 |
binary | 二进制字符集 | binary | 二进制排序规则 |
gbk | GBK 中文字符集 | gbk_chinese_ci | 中文不区分大小写的排序规则 |
big5 | Big5 中文字符集 | big5_chinese_ci | 中文不区分大小写的排序规则 |
latin2 | 中欧字符集 | latin2_general_ci | 一般不区分大小写的中欧字符集排序规则 |
cp1251 | 西里尔字符集 | cp1251_general_ci | 一般不区分大小写的西里尔字符集排序规则 |
euckr | 韩文字符集 | euckr_korean_ci | 韩文不区分大小写的排序规则 |
sjis | Shift-JIS 日文字符集 | sjis_japanese_ci | 日文不区分大小写的排序规则 |
utf16 | UTF-16 Unicode | utf16_general_ci | 一般不区分大小写的 UTF-16 排序规则 |
utf32 | UTF-32 Unicode | utf32_general_ci | 一般不区分大小写的 UTF-32 排序规则 |
utf8mb3 | UTF-8 Unicode (3字节) | utf8mb3_general_ci | 一般不区分大小写的 Unicode 排序规则 (与 utf8 等价) |
说明:
- 字符集 (Character Set):表示字符集的名称。
- 描述 (Description):对字符集的简单描述。
- 默认排序规则 (Default Collation):字符集的默认排序规则。
- 描述 (Description):对排序规则的简单描述。
这些字符集及其排序规则是 MySQL 数据库中常用的设置,具体使用哪种字符集和排序规则取决于应用的需求和数据的语言环境。
MySQL中 utf8 和 utf8mb4 字符集的区别(太长不看版)
- MySQL中的
utf8mb4才是真正的 UTF-8 - 想要存储 emoji 和其他特殊字符,使用
utf8mb4
MySQL中 utf8 和 utf8mb4 字符集的区别
utf8 和 utf8mb4 是两种字符编码方式,主要用于表示 Unicode 字符。它们的区别主要在于能够表示的字符范围和字符的存储方式。
-
utf8:
- utf8 是一种可变长度字符编码,可以使用 1 到 4 个字节来表示一个字符。
- 在 MySQL 中,
utf8编码实际上只支持最多 3 个字节的字符,这意味着它不能完全表示所有的 Unicode 字符,特别是一些较新的 emoji 和某些亚洲文字。
-
utf8mb4:
utf8mb4是 MySQL 中对 utf8 的一种扩展,支持完整的 4 字节字符编码。- 由于它能使用 4 个字节来表示字符,因此可以表示所有的 Unicode 字符,包括那些无法用
utf8表示的字符。
总结来说,utf8mb4 是 utf8 的超集,能够表示更多的字符。为了确保能够存储和处理所有 Unicode 字符,尤其是现代应用中常见的 emoji 和其他特殊字符,推荐使用 utf8mb4。
查看、删除数据库
- 查看所有数据库
-- 查看所有数据库
SHOW DATABASES;
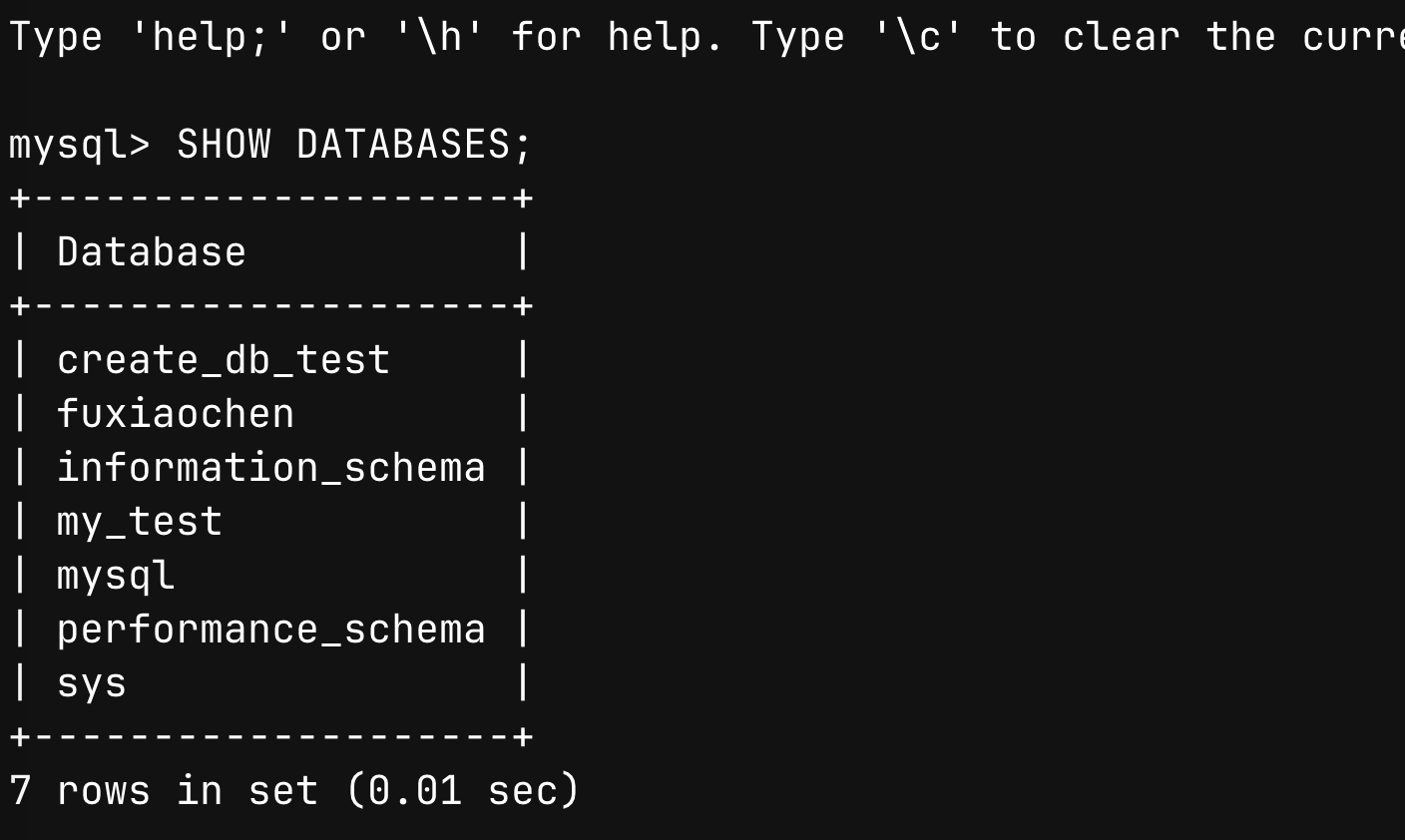
- 查看数据库创建语句:
SHOW CREATE DATABASE 数据库名;
-- 查看数据库创建语句
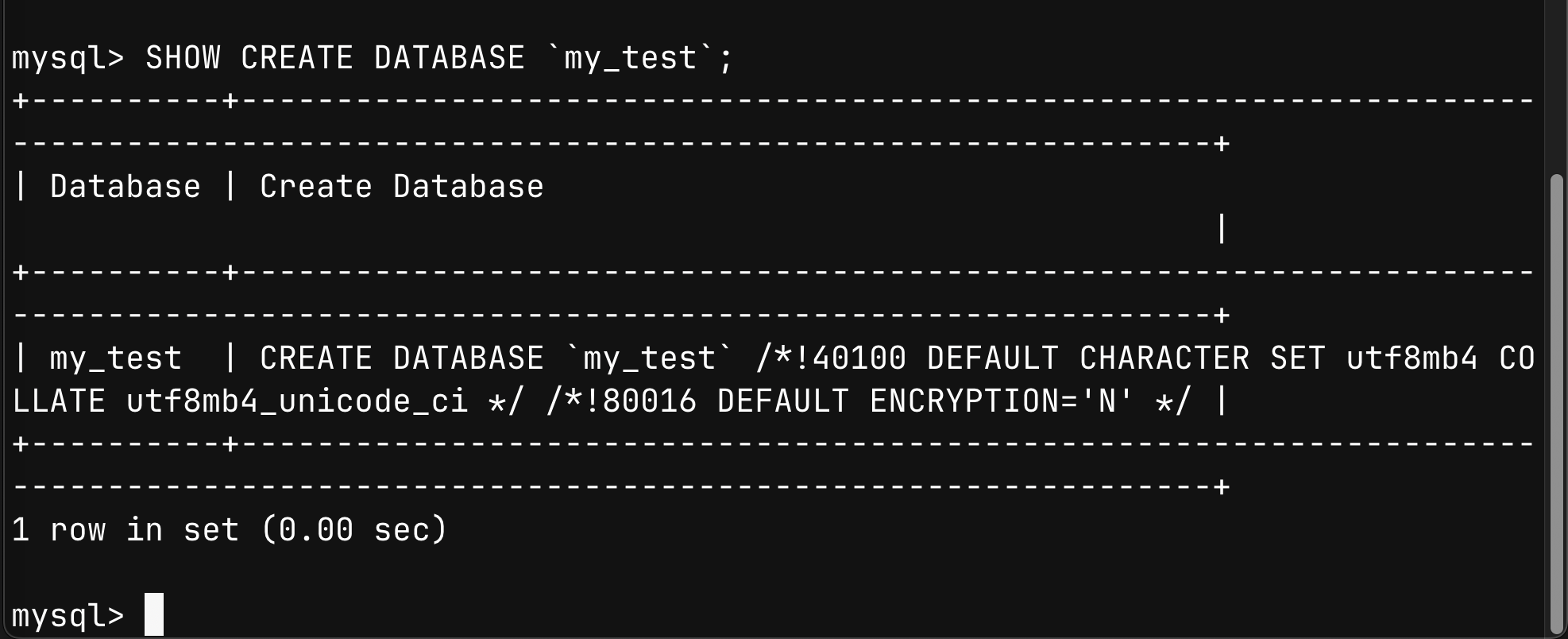
SHOW CREATE DATABASE `my_test`;
- 删除数据库(慎用,务必确认好是否需要备份,数据无价):
DROP DATABASE IF EXISTS 数据库名;
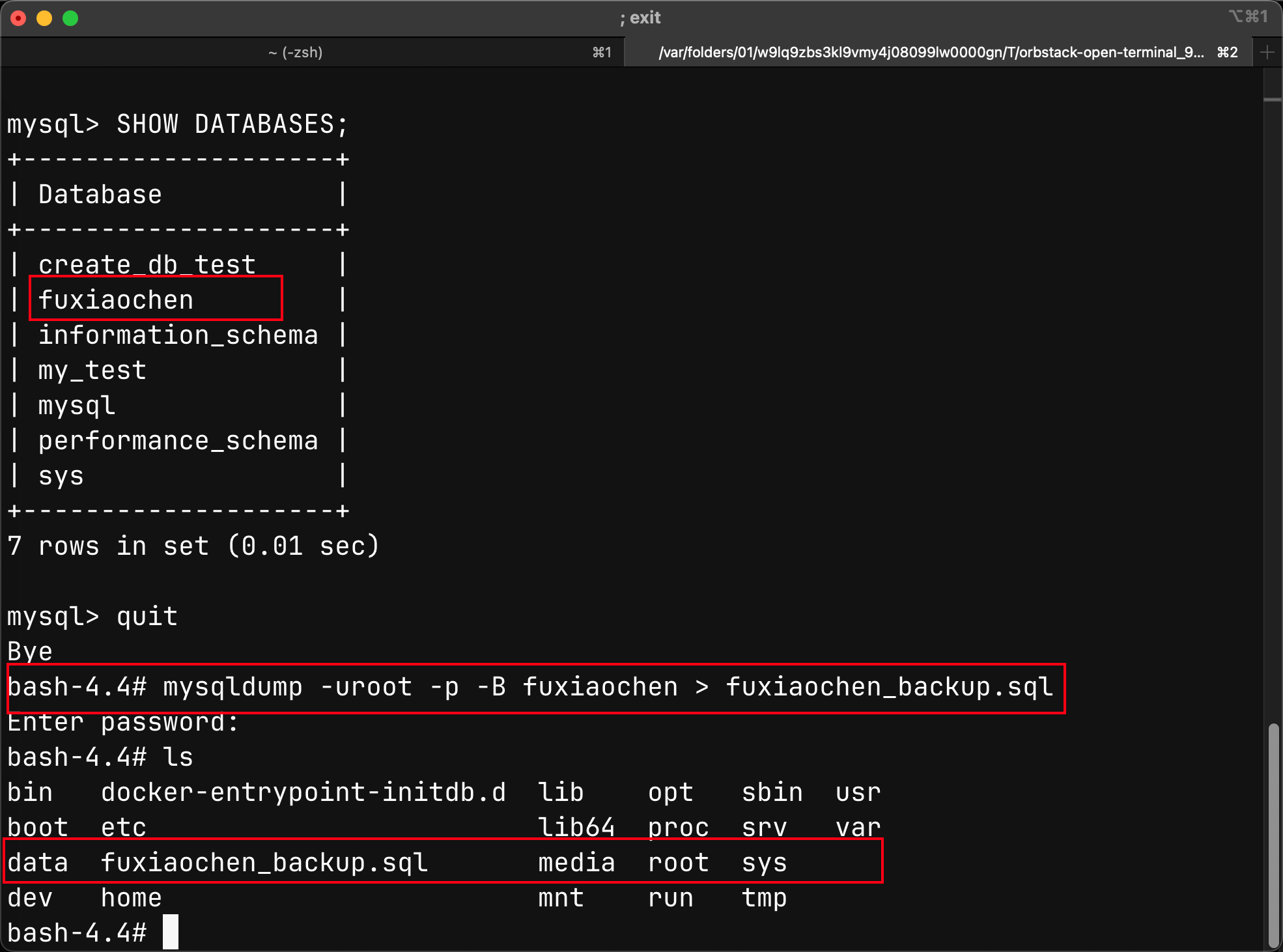
备份数据库
注意:mysqldump 是在命令行中执行,不是在 MySQL 的交互式命令里面执行
- 备份一个数据库:
mysqldump -u用户名 -p -B 数据库名 > 文件名.sql
- 备份某个数据库中的某些表:
mysqldump -u用户名 -p 数据库名 表1 表2 表3 > 文件名.sql - 备份多个数据库:
mysqldump -u用户名 -p -B 数据库1 数据库2 数据库3 > 文件名.sql
恢复数据库
使用登录命令进入到 MySQL 的命令行,然后执行 SOURCE 文件名.sql
创建表
具体的命令格式:
CREATE TABLE 表名 (
字段名 字段类型,
字段名 字段类型,
字段名 字段类型
...
) CHARACTER SET 字符集 COLLATE 排序规则 ENGINE 引擎;
- CHARACTER SET:不指定则为所在数据库字符集
- COLLATE:不指定则为所在数据库排序规则
- ENGINE:TODO:待补充
示例:
创建表前,我们需要指定在哪个数据库中创建表,使用
USE 数据库名;来指定
-- 创建表
-- 指定使用的数据库
USE `my_test`;
-- 创建 user 表
CREATE TABLE `user` (
`id` INT,
`name` VARCHAR(255),
`password` VARCHAR(30),
`birthday` DATE
) CHARACTER SET `utf8mb4` COLLATE `utf8mb4_general_ci`;
MySQL 常用数据类型
数据类型可分为以下几大类:
- 数值类型:
BIT、TINY INT、INT、BING INT、DOUBLE等 - 文本类型:
CHAR、VARCHAR、TEXT等 - 二进制类型:
BLOB、LONG BLOB等 - 时间日期类型:
DATETIME、TIMESTAMP等
数值类型
| 数据类型 | 说明 |
|---|---|
| BIT(M) | 位类型;M 指定位数,默认1,范围1~64 |
| TINYINT [UNSIGNED] 占1个字节 | 带符号的范围是 -128~127;无符号 0~255;默认是有符号 |
| SMALLINT [UNSIGNED] 占2个字节 | 带符号的范围是 -2^15~2^15-1;无符号 0~2^16-1 |
| MEDIUMINT [UNSIGNED] 占3个字节 | 带符号的范围是 -2^23~2^23-1;无符号 0~2^24-1 |
| INT [UNSIGNED] 占4个字节 | 带符号的范围是 -2^31~2^31-1;无符号 0~2^32-1 |
| BIGINT [UNSIGNED] 占8个字节 | 带符号的范围是 -2^63~2^63-1;无符号 0~2^64-1 |
| FLOAT [UNSIGNED] | 占4个字节 |
| DOUBLE [UNSIGNED] | 表示比 FLOAT 精度更大的小数,占8个字节 |
| DECIMAL(M,D) [UNSIGNED] | 定点数 M 指定长度,D 表示小数点的位数 |
文本类型
| 数据类型 | 说明 |
|---|---|
| CHAR(size) | 固定长度字符串,最大255 |
| VARCHAR(size) | 可变长度字符串,0~65535(2^16-1) |
二进制类型
| 数据类型 | 说明 |
|---|---|
| BLOB | 二进制数据 BLOB 0~2^16-1 |
| LONGBLOB | 二进制数据 LONGBLOB 0~2^32-1 |
时间日期类型
| 数据类型 | 说明 |
|---|---|
| DATE | 日期 YYYY-MM-DD |
| DATETIME | 日期时间 YYYY-MM-DD HH:mm:ss |
| TIMESTAMP | 时间戳,可用于自动记录 INSERT UPDATE 操作的时间 |
修改表
使用 ALTER TABLE 语句追加、修改或者删除列
- 添加列
-- 语法
ALTER TABLE 表名 ADD 列名 字段类型 ...;
-- 示例
ALTER TABLE `emp` ADD `image` VARCHAR(255) NOT NULL DEFAULT '' AFTER `resume`;
- 修改列
-- 语法
ALTER TABLE 表名 MODIFY 列名 字段类型;
-- 示例
ALTER TABLE `emp` MODIFY `job` VARCHAR(50);
- 删除列
-- 语法
ALTER TABLE 表名 DROP 列名;
-- 示例
ALTER TABLE `emp` DROP `sex`;
- 修改表名
-- 语法
RENAME TABLE 表名 TO 新表名;
-- 示例
RENAME TABLE `emp` TO `new_emp`;
- 修改表的字符集
-- 语法
ALTER TABLE 表名 CHARACTER SET 字符集;
-- 示例
ALTER TABLE `emp` CHARACTER SET `utf8`;
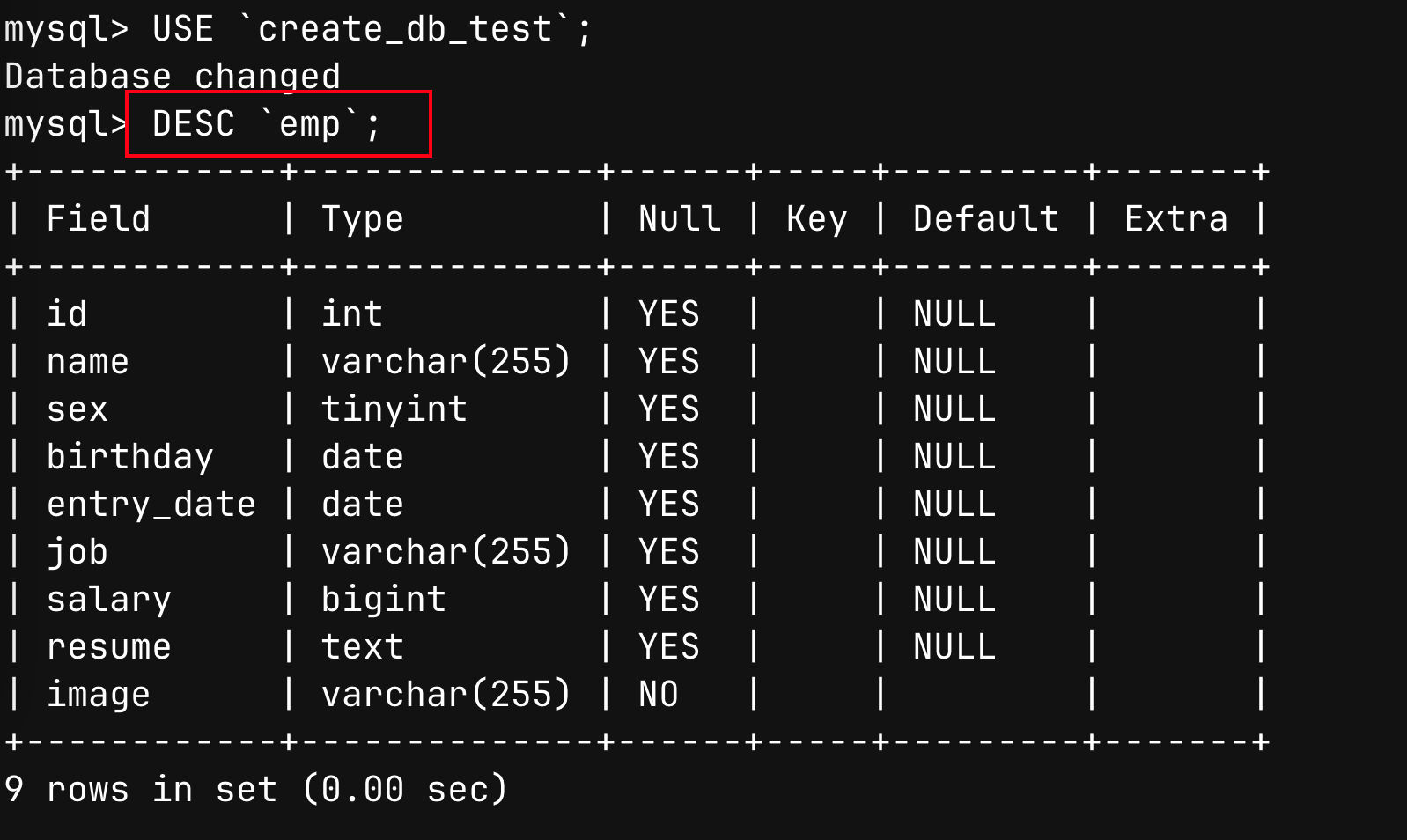
- 查看表的结构
-- 语法
DESC 表名;
-- 示例
DESC `emp`;
CRUD
Insert
使用 INSERT INTO 向表中插入数据有2种用法
- 不指定具体的列名,插入数据,插入数据的值的顺序和创建表的时候列的顺序和格式完全一致
语法:
INSERT INTO 表名 VALUES (value1, value2, xxx,...);
示例:
-- user 表的建表语句
CREATE TABLE `user` (
`id` INT,
`name` VARCHAR(255),
`password` VARCHAR(30),
`birthday` DATE
) CHARACTER SET `utf8mb4` COLLATE `utf8mb4_general_ci`;
INSERT INTO `user` VALUES (100, 'Tom', 'pwd123456', '2020-05-21');
- 手动指定列名插入数据,插入数据的值的顺序和类型和指定列名的顺序和类型一一对应
-- 插入一条数据,指定 (`id`, `name`, `password`, `birthday`) 列对应的值为 (100, 'Tom', 'pwd123456', '2020-05-21')
INSERT INTO `user` (`id`, `name`, `password`, `birthday`) VALUES (100, 'Tom', 'pwd123456', '2020-05-21');
-- 插入一条数据,指定 (`id`, `name`,) 列对应的值为 (200, 'Bob')
INSERT INTO `user` (`id`, `name`) VALUES (200, 'Bob');
Update
使用 UPDATE 修改表中的数据
UPDATE 表名 SET 列名1=值1, 列名2=值2 [WHERE 条件]
如果 UPDATE 不带 WHERE 条件表示更新这个表的所有记录,慎用不带 WHERE 条件的 UPDATE 语句
示例:
UPDATE `user` SET `id`=999, `name`='GG Bound' WHERE id=100;
Delete
使用 DELETE 修改表中的数据
DELETE 表名 [WHERE 条件]
如果 DELETE 不带 WHERE 条件表示删除这个表的所有记录,慎用不带 WHERE 条件的 DELETE 语句
示例:
-- 删除 user 表中 id 为 100 的数据
DELETE `user` WHERE id=100;
-- 删除 user 表中所有数据
DELETE `user`;
Select
基本语法
SELECT [DISTINCT] *|{column1, column2, column3...} FROM tablename;
注意事项:
SELECT指定查询哪些列的数据column指定列名*号代表查询所有列FROM指定查询哪张表DISTINCT可选,指显示结果时,是否去掉重复数据(要查询的记录,每个字段都相同才会去重)
示例:
-- 查询 user 表中所有列的数据
SELECT * FROM `user`;
-- 查询 user 表中 id 和 name 列的数据
SELECT `id`, `name` FROM `user`;
使用表达式对查询的列进行运算
SELECT *|{column1|expression, column2|expression, ...} FROM tablename;
在 SELECT 语句中可使用 AS 语句
SELECT column_name AS 别名 FROM tablename;
示例:
SELECT `id` AS `user_id`, `name` FROM `user`;
使用 WHERE 对查询记录进行过滤筛选
WHERE 中常用的运算符
- 比较运算符
| 运算符 | 介绍 |
|---|---|
| >、<、 <=、 >=、 =、 | 大于、小于 |
| <=、 >=、 = | 小于等于、大于等于、等于 |
| >< 、!= | 不等于(第一种写法)、不等于(第二种写法) |
| BETWEEN ...AND... | 显示在某一区间的值 |
| IN(列表) | 显示在IN列表中的值,例:IN(100, 200) |
| LIKE 'pattern'、NOT LIKE 'pattern' | 模糊查询 |
| IS NULL | 判断是否为空(NULL) |
- 逻辑运算符
| 运算符 | 介绍 |
|---|---|
| AND | 多个条件同时成立 |
| OR | 多个条件任意一个成立 |
| NOT | 不成立,例:WHERE NOT(id=100) |
LIKE 和 UNLIKE 模糊匹配补充
在 MySQL 中,LIKE 操作符用于在查询中进行模式匹配。它可以用于在文本字段中搜索特定的模式。
LIKE 操作符通常与通配符一起使用,通配符可以代表任意字符序列(包括空字符序列)。以下是常用的通配符:
%:表示任意字符序列(包括空字符序列)。_:表示任意单个字符。
以下是一些使用 LIKE 操作符的示例:
-
查找以 "abc" 开头的记录:
SELECT * FROM your_table WHERE your_column LIKE 'abc%'; -
查找以 "abc" 结尾的记录:
SELECT * FROM your_table WHERE your_column LIKE '%abc'; -
查找包含 "abc" 的记录:
SELECT * FROM your_table WHERE your_column LIKE '%abc%'; -
查找以 "a" 开头,以 "c" 结尾,中间包含任意字符的记录:
SELECT * FROM your_table WHERE your_column LIKE 'a%c';
使用 ORDER BY 排序查询结果
SELECT `column1`, `column2`, `column3` ... FROM `table_name` ORDER BY `column_name` ASC|DESC
-
ORDER BY指定排序的列既可以是表中的列名也可以是SELECT语句后指定的列名 -
ASC升序(默认值)、DESC降序 -
ORDER BY需要放到SELECT语句的结尾
'%3e%20%3cpath%20fill='%2300678c'%20fill-rule='evenodd'%20d='M203.801%20178.21c-9.79-.272-17.385.731-23.75%203.409c-1.833.736-4.774.736-5.016%203.043c.98.968%201.098%202.552%201.957%203.894c1.467%202.435%204.041%205.715%206.365%207.417l7.834%205.598c4.774%202.917%2010.16%204.622%2014.811%207.542c2.694%201.704%205.386%203.894%208.08%205.721c1.372.973%202.203%202.558%203.918%203.163v-.368c-.856-1.091-1.103-2.672-1.956-3.894l-3.677-3.526c-3.547-4.744-7.957-8.884-12.731-12.287c-3.918-2.677-12.484-6.326-14.076-10.825l-.241-.273c2.689-.272%205.872-1.219%208.445-1.949c4.165-1.091%207.957-.851%2012.238-1.945l5.88-1.704v-1.091c-2.204-2.189-3.795-5.11-6.119-7.176c-6.242-5.353-13.102-10.586-20.203-14.965c-3.794-2.432-8.692-4.017-12.731-6.081c-1.473-.731-3.918-1.096-4.774-2.312c-2.209-2.672-3.43-6.204-5.021-9.369l-10.037-21.168c-2.203-4.745-3.553-9.49-6.242-13.869c-12.611-20.683-26.324-33.212-47.38-45.502c-4.527-2.555-9.913-3.654-15.64-4.99l-9.18-.49c-1.962-.851-3.919-3.164-5.633-4.26c-6.978-4.38-24.974-13.868-30.12-1.363c-3.305%207.907%204.899%2015.692%207.684%2019.709c2.085%202.798%204.774%205.96%206.247%209.124c.823%202.067%201.098%204.259%201.957%206.449c1.956%205.352%203.794%2011.316%206.365%2016.306c1.372%202.555%202.813%205.235%204.527%207.545c.98%201.363%202.695%201.947%203.06%204.136c-1.715%202.435-1.833%206.081-2.813%209.127c-4.409%2013.748-2.694%2030.78%203.548%2040.902c1.962%203.04%206.585%209.734%2012.858%207.177c5.509-2.19%204.28-9.124%205.871-15.208c.37-1.458.124-2.432.856-3.408v.273l5.021%2010.097c3.795%205.961%2010.408%2012.167%2015.914%2016.306c2.936%202.19%205.263%205.964%208.934%207.3v-.368h-.241c-.736-1.091-1.839-1.582-2.818-2.433c-2.203-2.189-4.651-4.867-6.366-7.299c-5.139-6.812-9.666-14.357-13.708-22.142c-1.961-3.771-3.676-7.908-5.262-11.679c-.741-1.461-.741-3.654-1.962-4.379c-1.839%202.672-4.527%204.99-5.88%208.273c-2.327%205.23-2.568%2011.679-3.424%2018.371c-.494.122-.275%200-.494.272c-3.913-.97-5.263-4.99-6.73-8.393c-3.672-8.638-4.287-22.507-1.104-32.484c.856-2.555%204.533-10.585%203.065-13.018c-.74-2.312-3.183-3.648-4.533-5.475c-1.591-2.312-3.3-5.23-4.403-7.785c-2.936-6.817-4.404-14.357-7.59-21.17c-1.473-3.164-4.041-6.45-6.124-9.367c-2.327-3.286-4.892-5.599-6.73-9.49c-.612-1.363-1.468-3.528-.489-4.99c.242-.973.735-1.363%201.71-1.581c1.59-1.364%206.124.365%207.715%201.09c4.527%201.827%208.322%203.529%2012.117%206.081c1.715%201.216%203.553%203.529%205.756%204.14h2.574c3.918.85%208.322.272%2011.99%201.363c6.49%202.072%2012.364%205.11%2017.632%208.398c16.035%2010.098%2029.26%2024.454%2038.193%2041.611c1.468%202.798%202.08%205.353%203.43%208.273c2.574%205.964%205.757%2012.045%208.322%2017.888c2.574%205.718%205.021%2011.562%208.693%2016.306c1.838%202.555%209.18%203.891%2012.484%205.23c2.45%201.091%206.242%202.073%208.451%203.409c4.159%202.555%208.322%205.475%2012.237%208.273c1.956%201.456%208.081%204.499%208.445%206.926zM78.958%2072.487a19.569%2019.569%200%200%200-5.015.608v.273h.241c.98%201.947%202.695%203.286%203.918%204.99l2.818%205.84l.242-.272c1.714-1.216%202.573-3.163%202.573-6.08c-.735-.851-.856-1.705-1.468-2.556c-.735-1.216-2.326-1.827-3.309-2.797z'%20clip-rule='evenodd'%20/%3e%20%3c/g%3e%20%3cdefs%3e%20%3cclipPath%20id='skillIconsMysqlLight0'%3e%20%3cpath%20fill='white'%20d='M38%2038h180v180H38z'%20/%3e%20%3c/clipPath%3e%20%3c/defs%3e%20%3c/g%3e%20%3c/svg%3e)
'%3e%20%3cpath%20fill='white'%20fill-rule='evenodd'%20d='M203.801%20178.21c-9.79-.272-17.385.731-23.75%203.409c-1.833.736-4.774.736-5.016%203.043c.98.968%201.098%202.552%201.957%203.894c1.467%202.435%204.041%205.715%206.365%207.417l7.834%205.598c4.774%202.917%2010.16%204.622%2014.811%207.542c2.694%201.704%205.386%203.894%208.08%205.721c1.372.973%202.203%202.558%203.918%203.163v-.368c-.856-1.091-1.103-2.672-1.956-3.894l-3.677-3.526c-3.547-4.744-7.957-8.884-12.731-12.287c-3.918-2.677-12.484-6.326-14.076-10.825l-.241-.273c2.689-.272%205.872-1.219%208.445-1.949c4.165-1.091%207.957-.851%2012.238-1.945l5.88-1.704v-1.091c-2.204-2.189-3.795-5.11-6.119-7.176c-6.242-5.353-13.102-10.586-20.203-14.965c-3.794-2.432-8.692-4.017-12.731-6.081c-1.473-.731-3.918-1.096-4.774-2.312c-2.209-2.672-3.43-6.204-5.021-9.369l-10.037-21.168c-2.203-4.745-3.553-9.49-6.242-13.869c-12.611-20.683-26.324-33.212-47.38-45.502c-4.527-2.555-9.913-3.654-15.64-4.99l-9.18-.49c-1.962-.851-3.919-3.164-5.633-4.26c-6.978-4.38-24.974-13.868-30.12-1.363c-3.305%207.907%204.899%2015.692%207.684%2019.709c2.085%202.798%204.774%205.96%206.247%209.124c.823%202.067%201.098%204.259%201.957%206.449c1.956%205.352%203.794%2011.316%206.365%2016.306c1.372%202.555%202.813%205.235%204.527%207.545c.98%201.363%202.695%201.947%203.06%204.136c-1.715%202.435-1.833%206.081-2.813%209.127c-4.409%2013.748-2.694%2030.78%203.548%2040.902c1.962%203.04%206.585%209.734%2012.858%207.177c5.509-2.19%204.28-9.124%205.871-15.208c.37-1.458.124-2.432.856-3.408v.273l5.021%2010.097c3.795%205.961%2010.408%2012.167%2015.914%2016.306c2.936%202.19%205.263%205.964%208.934%207.3v-.368h-.241c-.736-1.091-1.839-1.582-2.818-2.433c-2.203-2.189-4.651-4.867-6.366-7.299c-5.139-6.812-9.666-14.357-13.708-22.142c-1.961-3.771-3.676-7.908-5.262-11.679c-.741-1.461-.741-3.654-1.962-4.379c-1.839%202.672-4.527%204.99-5.88%208.273c-2.327%205.23-2.568%2011.679-3.424%2018.371c-.494.122-.275%200-.494.272c-3.913-.97-5.263-4.99-6.73-8.393c-3.672-8.638-4.287-22.507-1.104-32.484c.856-2.555%204.533-10.585%203.065-13.018c-.74-2.312-3.183-3.648-4.533-5.475c-1.591-2.312-3.3-5.23-4.403-7.785c-2.936-6.817-4.404-14.357-7.59-21.17c-1.473-3.164-4.041-6.45-6.124-9.367c-2.327-3.286-4.892-5.599-6.73-9.49c-.612-1.363-1.468-3.528-.489-4.99c.242-.973.735-1.363%201.71-1.581c1.59-1.364%206.124.365%207.715%201.09c4.527%201.827%208.322%203.529%2012.117%206.081c1.715%201.216%203.553%203.529%205.756%204.14h2.574c3.918.85%208.322.272%2011.99%201.363c6.49%202.072%2012.364%205.11%2017.632%208.398c16.035%2010.098%2029.26%2024.454%2038.193%2041.611c1.468%202.798%202.08%205.353%203.43%208.273c2.574%205.964%205.757%2012.045%208.322%2017.888c2.574%205.718%205.021%2011.562%208.693%2016.306c1.838%202.555%209.18%203.891%2012.484%205.23c2.45%201.091%206.242%202.073%208.451%203.409c4.159%202.555%208.322%205.475%2012.237%208.273c1.956%201.456%208.081%204.499%208.445%206.926zM78.958%2072.487a19.569%2019.569%200%200%200-5.015.608v.273h.241c.98%201.947%202.695%203.286%203.918%204.99l2.818%205.84l.242-.272c1.714-1.216%202.573-3.163%202.573-6.08c-.735-.851-.856-1.705-1.468-2.556c-.735-1.216-2.326-1.827-3.309-2.797z'%20clip-rule='evenodd'%20/%3e%20%3c/g%3e%20%3cdefs%3e%20%3cclipPath%20id='skillIconsMysqlDark0'%3e%20%3cpath%20fill='white'%20d='M38%2038h180v180H38z'%20/%3e%20%3c/clipPath%3e%20%3c/defs%3e%20%3c/g%3e%20%3c/svg%3e)